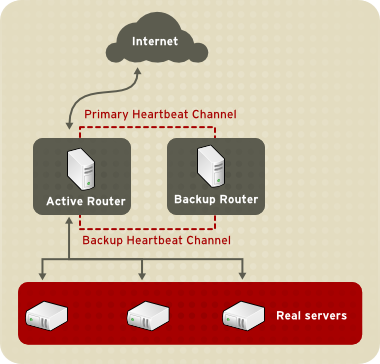
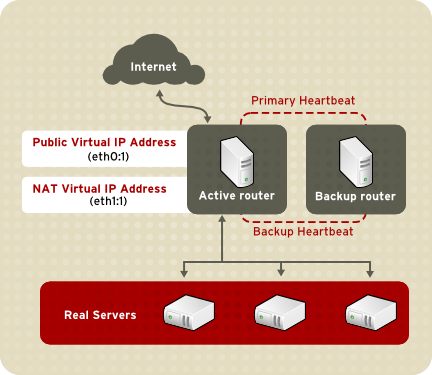
เกิดขึ้นครั้งแรกเมื่อปี 1973 โดยองค์กรที่ชื่่อว่า ARPANET (Advanced Research Project Agency Network) โดยมีวัตถุประสงค์ นำเอาเทคโนโลยีเข้ามาช่วยประหยัดต้นทุนการติดต่อสื่อสาร โดยการใช้งานระบบเครือข่ายให้มีประโยชน์และมีประสิทธิภาพมากขึ้น
หรือชื่ออื่น IP Telephony, Internet telephony, หรือ Digital Phone เป็นการสื่อสารทางเสียงผ่านโครงข่ายอินเทอร์เน็ต หรือโครงข่ายอื่นๆ ที่ใช้อินเทอร์เน็ตโปรโตคอล สัญญาณเสียงจะถูกตัดแบ่งเป็นแพ็คเก็ตวิ่งผ่านไปบนโครงข่ายที่ใช้สำหรับการสื่อสารข้อมูลทั่วไป แทนการใช้วงจรเฉพาะตามวิธีการสื่อสารในระบบโทรศัพท์แบบดั้งเดิม เปรียบได้กับการให้รถยนต์วิ่งแทรกกันได้ตามช่องว่างที่มีอยู่ของถนน แทนการให้รถยนต์คันเดียวจองถนนวิ่งแบบผูกขาด ข้อดีของวีโอไอพีก็คือการสามารถใช้โครงข่ายได้อย่างมีประสิทธิภาพ ทำให้สามารถให้บริการได้ในอัตราค่าบริการที่ถูกลงมา
VoIP สามารถแบ่งได้เป็น 3 ลักษณะ
1. คอมพิวเตอร์ส่วนบุคคล ไปยัง คอมพิวเตอร์ส่วนบุคคล ( PC to PC )
PC มีการติดตั้ง sound card และไมโครโฟน ที่เชื่อมต่ออยู่กับเครือข่าย IP การประยุกต์ใช้ PC และ IP-enabled telephones สามารถสื่อสารกันได้แบบจุดต่อจุด หรือ แบบจุดต่อหลายจุด โดยอาศัย software ทางด้าน IP telephony

2. คอมพิวเตอร์ส่วนบุคคล ไปยัง โทรศัพท์พื้นฐาน ( PC to Phone )
เป็นการเชื่อมเครือข่ายโทรศัพท์เข้ากับ เครือข่าย IP ทำให้โดยอาศัย Voice trunks ที่สนับสนุน voice packet ทำให้สามารถใช้ PC ติดต่อกับ โทรศัพท์ระบบปกติได้

3. โทรศัพท์กับโทรศัพท์ ( Telephony )
เป็นการใช้โทรศัพท์ธรรมดา ติดต่อกับโทรศัพท์ธรรมดา แต่ในกรณีนี้จริงๆแล้วประกอบด้วยขั้นตอนการส่งเสียงบนเครือข่าย Packet ประเภทต่างๆซึ่งทั้งหมดติดต่อกันระหว่างชุมสายโทรศัพท์ (PSTN) การติดต่อกับ PSTN หรือ การใช้โทรศัพท์ร่วมกับเครือข่ายข้อมูลจำเป็นต้องใช้ gateway

สำหรับมาตราฐานของวีโอไอพี มี 2 รูปแบบ คือ
1. H.323 Standard
สำหรับมาตรฐาน H.323 นั้น จริงๆ แล้วไม่ได้ถูกออกแบบมาให้ใช้งานกับระบบเครือข่ายที่ใช้ Internet Protocol (IP) นอกจากนั้นมาตรฐาน H.323 ยังมีการทำงานที่ค่อนข้างช้า โดยปกติแล้วเราจะเสนอการใช้งานมาตรฐาน H.323 ให้กับลูกค้าก็ต่อเมื่อในระบบเดิมของลูกค้ามีการใช้งานมาตรฐาน H.323 อยู่แล้วเท่านั้น
- มาตรฐาน H.323 เป็นมาตรฐานภายใต้ ITU-T (International Telecommunications Union) Standard
- ในตอนแรกนั้น มาตรฐาน H.323 ได้ถูกพัฒนาขึ้นมาเพื่อเป็นมาตรฐานสำหรับการทำ Multimedia Conferencing บนระบบเครือข่าย LAN เป็นหลัก แต่มาในตอนหลังจึงถูกพัฒนาให้ครอบคลุมถึงการทำงานกับเทคโนโลยี VoIP ด้วย
- มาตรฐาน H.323 สามารถรองรับการทำงานได้ทั้งแบบ Point-to-Point Communications และแบบ Multi-Point Conferences
- อุปกรณ์ต่างๆ จากหลากหลายยี่ห้อ หรือหลายๆ Vendors นั้นสามารถที่จะทำงานร่วมกัน (Inter-Operate) ผ่านมาตรฐาน H.323 ได้
2. SIP (Session Initiation Protocol) Standard
มาตรฐาน SIP นั้นถือเป็นมาตรฐานใหม่ในการใช้งานเทคโนโลยี VoIP โดยที่มาตรฐาน SIP นั้น ได้ถูกออกแบบมาให้ใช้งานกับระบบ IP โดยเฉพาะ ซึ่งโดยปกติแล้วเราจะแนะนำให้ลูกค้าใหม่ที่จะมีการใช้งาน VoIP ให้มีการใช้งานอยู่บนมาตรฐาน SIP...
- มาตรฐาน SIP นั้นเป็นมาตรฐานภายใต้ IETF Standard ซึ่งถูกออกแบบมาสำหรับการเชื่อมต่อ VoIP
- มาตรฐาน SIP นั้นจะเป็นมาตรฐาน Application Layer Control Protocol สำหรับการเริ่มต้น (Creating), การปรับเปลี่ยน (Modifying) และการสิ้นสุด (Terminating) ของ Session หรือการติดต่อสื่อสารหนึ่งครั้ง
- มาตรฐาน SIP จะมีสถาปัตยกรรมการทำงานคล้ายคลึงการทำงานแบบ Client-Server Protocol
- เป็นมาตรฐานที่มี Reliability ที่ค่อนข้างสูง Vendors นั้นสามารถที่จะทำงานร่วมกัน (Inter-Operate) ผ่านมาตรฐาน H.323 ได้

การส่งสัญญาณเสียง
ครั้งเมื่อมีเครือข่ายไอพีกว้างขวางและเชื่อมโยงกันมากขึ้น ความต้องการส่งสัญญาณข้อมูลเสียงที่ได้คุณภาพก็เกิดขึ้น สิ่งที่สำคัญ คือระบบประกันคุณภาพการสื่อสาร โดยจัดลำดับความสำคัญ หรือจองช่องสัญญาณไว้ให้ก่อน ระบบการสื่อสารในรูปแบบใหม่นี้ จะต้องกระทำโดยเราเตอร์
การส่งเสียงบนเครือข่ายไอพี หรือเรียกว่า VoIP-Voice Over IP เป็นระบบที่นำสัญญาณข้อมูลเสียงมาบรรจุลงเป็นแพ็กเก็ต ไอพี แล้วส่งไปโดยที่เราเตอร์มีวิธีการปรับตัวเพื่อรับสัญญาณแพ็กเก็ต และยังแก้ปัญหาบางอย่างให้ เช่น การบีบอัดสัญญาณเสียง ให้มีขนาดเล็กลง การแก้ปัญหาเมื่อมีบางแพ็กเก็ตสูญหาย หรือได้มาล่าช้า

ระบบ VoIP เป็นระบบที่นำสัญญาณเสียงที่ผ่านการดิจิไตซ์ โดยหนึ่งช่องเสียงเมื่อแปลงเป็นข้อมูลจะมีขนาด 64 กิโลบิตต่อ วินาที การนำข้อมูลเสียงขนาด 64 Kbps นี้ ต้องนำมาบีบอัด โดยทั่วไปจะเหลือประมาณ 10 Kbps ต่อช่องสัญญาณเสียงแล้วจึง บรรจุลงในไอพีแพ็กเก็ต เพื่อส่งผ่านทางเครือข่ายไอพี
การสื่อสารผ่านทางเครือข่ายไอพีต้องมีเราเตอร์ที่ทำหน้าที่พิเศษเพื่อ ประกันคุณภาพช่องสัญญาณไอพีนี้ เพื่อให้ข้อมูลไปถึง ปลายทางหรือกลับมาได้อย่างถูกต้อง และอาจมีการให้สิทธิพิเศษก่อนแพ็กเก็ตไอพีอื่น เพื่อการให้บริการที่ทำให้เสียงมีคุณภาพ
จากระบบดังกล่าวนี้เอง จึงสามารถนำมาประยุกต์ใช้กับระบบเชื่อมโยงเครือข่ายโทรศัพท์ระหว่างองค์กร โดยองค์กรสามารถ ใช้ระบบสื่อสารทางโทรศัพท์ผ่านทางเครือข่ายไอพี

ตัวอย่าง Application การใช้งานเทคโนโลยี VoIP
1. PBX to PBX Connection
* ทั้ง 2 ฝั่งของสำนักงานจะสามารถใช้งานตู้สาขา PBX ของสำนักงานอีกฝั่งเปีรยบเสมือนตู้สาขา PBX ของฝั่งตัวเอง
* Users ภายในไม่จำเป็นต้องทำการ Dial ออกไปบนระบบโทรศัพท์ PSTN เพื่อทำการเชื่อมต่อเข้ากับตู้สาขา PBX ของสำนักงานอีกฝั่ง

* เป็นการเชื่อมต่อที่สำนักงานใหญ่ขยายการเชื่อมต่อตู้สาขา PBX ไปที่สำนักงานสาขาที่ไม่มีตู้ PBX ใช้งานอยู่
* ทางสำนักงานสาขาสามารถใช้งานตู้ PBX ผ่านทางสำนักงานใหญ่ได้เสมือนกับเป็นตู้สาขา PBX ของฝั่งตนเอง

* เป็นการเชื่อมต่อที่ยินยอมให้ Remote User ฝั่งสำนักงานใหญ่สามารถใช้งานโทรศัพท์เข้ามาที่สำนักงานใหญ่ แล้วใช้ระบบเครือข่ายของสำนักงานใหญ่เชื่อมต่อไปยังสำนักงานสาขาผ่าน เทคโนโลยี VoIP เพื่อสามารถใช้ งานโทรศัพท์ในพื้นที่ของสำนักงานสาขาได้โดยเสียค่าบริการในอัตราของพื้นที่ ของสำนักงานสาขานั้น ๆ

* ผู้ให้บริการต่าง ๆ เช่น ISP สามารถที่จะเสนอบริการเสริมต่าง ๆ ทางด้าน VoIP บนระบบเครือข่ายความเร็วสูงที่มีการใช้งานอยู่เดิมแล้ว

อุปกรณ์เชื่อมต่อ เพื่อใช้งาน VoIP
สำหรับอุปกรณ์ในการเชื่อมต่อกับระบบ VoIP ไม่ว่าระบบ VoIP จะเป็นลักษณะ SoftSwitch หรือ HardSwitch อุปกรณ์ที่ใช้เชื่อมต่อ ก็ยังทำหน้าที่ 2 อย่างหลัก ๆ คือ
1. ทำหน้าที่แปลงสัญญาณเสียง,ภาพที่อยู่ในรูปแบบอนาล๊อกให้อยู่ในรูปแบบดิจิตอล
2. ทำหน้าที่บีบอัดข้อมูลเสียงมภาพที่อยู่ในรูปแบบดิจิตอล ให้มีขนาดที่เล็กลง เพื่อให้ใช้เวลาที่ส่งผ่านได้เร็วขึ้น
อุปกรณ์ที่ใช้เชื่อมต่อกับระบบ VoIP นั้น แบ่งออกได้ 2 ประเภทคือ
1. ที่เป็น Software ซึ่งมักจะเรียกกันว่า SoftPhone ข้อดีสำหรับการใช้งาน SoftPhone ไม่ต้องเสียเงินซื้ออุปกรณ์ที่เป็น Hardware เพราะ SoftPhone ส่วนให้มีให้ Download ฟรี นอกเสียจาก ต้องการ SoftPhone ที่มีความสามารถพิเศษเช่น สามารถส่งผ่านข้อมูลได้ทั้งภาพและเสียง หรือ สามารถใช้สำหรับการประชุมหลาย ๆ คู่สาย สำหรับข้อเสียคือ ในขณะที่ใช้งาน,รอการติดต่อ จำเป็นจะต้องเปิดเครื่องคอมพิวเตอร์ไว้ จึงทำให้ไม่สะดวกมากนัก และคุณภาพเสียงของ SoftPhone ยังขึ้นอยู่กับประสิทธิภาพของคอมพิวเตอร์ด้วย
2. ที่เป็น Hardware ไม่ว่าจะเป็น IP Phone, IP Video Phone, Phone Adapter, VoIP Gate หรือ Wi-Fi Phone ให้คุณภาพเสียงที่ดี แต่ก็ต้องศึกษาคุณสมบัติของตัวอุปกรณ์ เพราะบางครั้งอาจไม่รองรับกับระบบ VoIP ที่เชื่อมต่อ
ประโยชน์ของระบบวีโอไอพี
* ค่าใช้จ่ายในการสื่อสารถูกลงและสะดวกสบายมากยิ่งขึ้น
* ไม่มีขีดจำกัดในการขยายเครือข่าย ทุกที่ทั่วโลก ที่สามารถเชื่อมต่ออินเตอร์เน็ตได้
* เพิ่มความยืดหยุ่นในการติดต่อสื่อสาร ระหว่างสาขาขององค์กร หรือองค์กรกับองค์กร
* สามารถยุบรวมระบบเครือข่าย ทำให้ลดการเดินสาย Cable ใหม่
* รอบรับการขยายตัวของระบบในอนาคต
* ลดค่าใช้จ่ายในการดูแลและจัดการระบบ
* สามารถใช้งานร่วมกับอุปกรณ์สือสารไร้สายอื่่น ๆ เช่น โทรศัพท์มือถือ และ PDA
* เพิ่มประสิทธิภาพในการติดต่อกับลูกค้า โดยการพัฒนาต่อยอด เช่น เชื่อมกับระบบ CRM
จุดด้อยของวีโอไอพี
จุดด้อยของวีโอไอพีก็คือ ในบางกรณีคุณภาพเสียงอาจจะไม่ดีเท่าโทรศัพท์ปกติ และอาจจะมีการดีเลย์หรือการที่สัญญาณเสียงเดินทางมาช้า ทำให้พูดสวนกันไม่ได้ถนัด ต้องรอให้แต่ละฝ่ายพูดให้จบก่อนจึงจะพูดได้ แต่ปัญหานี้ได้รับการปรับปรุงขึ้นมาอย่างต่อเนื่องจนแทบจะไม่มีความแตกต่างอีกต่อไป ข้อเสียอีกประการหนึ่งก็คือ โทรศัพท์วีโอไอพี จะใช้งานไม่ได้เมื่อไฟฟ้าดับ หรืออินเทอร์เน็ตเกิดขัดข้อง
อนาคตของวีโอไอพี
วีโอไอพี หรือที่มักจะเรียกกันย่อๆว่าวอยส ์จะได้รับความนิยมมากขึ้น เนื่องจากคุณภาพที่ได้รับปรับปรุงและค่าใช้จ่ายที่ถูก จนในที่สุดอาจจะกลายเป็นบริการฟรี เช่น เดียวกับการใช้งานอินเทอร์เน็ตอื่นๆ เช่น การสืบค้นเว็บไซต์ การใช้อีเมล เพราะอันที่จริงก็ไม่มีความแตกต่างกันมากนัก ผู้ใช้บริการเพียงแต่จ่ายค่าเชื่อมต่ออินเทอร์เน็ตเท่านั้น
ทิศทางบริการแห่งยุค
Voice over IP เกิดขึ้นพร้อมๆ กับการให้บริการอินเทอร์เน็ต และได้กลายเป็นบริการยอดนิยมของผู้ที่เชี่ยวชาญด้านคอมพิวเตอร์ และนักศึกษา ซึ่งมีเวลาแต่ไม่มีเงิน เมื่อไม่นานมานี้ และในปัจจุบัน Voice over IP ก็กำลังได้รับความนิยมจากผู้ใช้เพิ่มมากขึ้นเรื่อยๆ การไม่สามารถเปิดให้บริการโทรศัพท์ด้วยเสียงผ่านอินเทอร์เน็ตจากเครือข่าย ที่มีอยู่เดิม อาจทำให้ผู้ให้บริการ เช่น เวอริซอน, เอสบีซี และเบลล์เซาธ์ ต้องสูญเสียส่วนแบ่งในตลาดโทรคมนาคมมูลค่า 200,000 ล้านดอลลาร์ได้ เนื่องจาก เมื่อใช้ Voice over IP ลูกค้ามีอิสระในการใช้เครือข่ายของผู้ให้บริการเดิม หรือจะเปลี่ยนผู้ให้บริการใหม่ อย่างเช่น บริษัทผู้ให้บริการทีวีตามสาย (เคเบิล ทีวี) หรือธุรกิจเกิดใหม่ อย่าง Net2Phone และ Vonage ได้ ประกอบกับ การใช้งาน Voice over IP ไม่จำเป็นต้องโทรศัพท์ผ่านพีซีที่ใช้ไมโครโฟนเป็นอุปกรณ์เสริมอีกต่อไป แม้ว่าอุปกรณ์ดังกล่าว กำลังจะกลับมาอีกครั้งตามกระแสนิยมบริการ อย่าง Skype ซึ่งพัฒนาขึ้นโดยอาศัยสถาปัตยกรรมของคาซา และทำให้การโทรศัพท์แบบพีซีกับพีซีง่ายขึ้น ขณะที่คิดค่าธรรมเนียมเหมือนโทรศัพท์ทั่วไป คือ เพียง 100 ดอลลาร์เท่านั้น นับตั้งแต่เปิดตัวไปเมื่อเดือนเมษายนที่ผ่านมา โวเนจ ผู้ให้บริการ Voice over IP ชั้นนำ สามารถดึงดูดให้ลูกค้า 85,000 คน จ่ายค่าบริการ 15 - 35 ดอลลาร์ต่อเดือน
แนวโน้มวงการโทรคมฯ
เมื่อเร็วๆนี้ บริษัท นีเมอร์เทส รีเสิร์ช ในชิคาโก ทำสำรวจ 42 บริษัท ซึ่งคิดเป็น 70% ของบริษัทที่มีรายได้มากกว่า 1,000 ล้านดอลลาร์ และพบว่า ประชาชนเกือบ 2 ใน 3 ใช้โทรศัพท์ผ่านอินเทอร์เน็ต ขณะที่อีก 20% ที่เหลือ กำลังทดลองใช้เทคโนโลยีดังกล่าว จึงไม่แปลกใจว่าทำไมเมื่อเดือนธันวาคมที่ผ่านมา เอที แอนด์ ที, เควสต์, คอกซ์ คอมมิวนิเคชันส์, และไทม์ วอร์เนอร์ เทเลคอม จึงตบเท้าทยอยเปิดตัวบริการ Voice over IP ของตัวเอง
Voice over IP สร้างความตื่นเต้นให้กับลูกค้า นางแคธี มาร์ติน รองประธานอาวุโสเอที แอนด์ ที ผู้ซึ่งผลักดันให้บริการโทรศัพท์ผ่านอินเทอร์เน็ต ของมา เบลล์ กลายเป็นบริการยอดนิยม 100 อันดับแรกในตลาดผู้บริโภคทั่วไปและองค์กรธุรกิจของสหรัฐ กล่าว พร้อมเสริมว่า คำว่า แจ๋ว ไม่ได้ถูกนำมาใช้ในภาคโทรคมนาคมเลย นับตั้งแต่การมาถึงของโทรศัพท์ในทศวรรษ 1950 เป็นต้นมา แต่ความยืดหยุ่นของโทรศัพท์ผ่านอินเทอร์เน็ต อาจทำให้ผู้ใช้ต้องอุทานคำดังกล่าว เพื่อแสดงออกถึงความพอใจในการใช้งาน
ขณะที่นายเดวิด ไอเซนเบิร์ก ที่ปรึกษาด้านโทรคมนาคมอิสระ ขยายความเรื่องความยืดหยุ่นของบริการ Voice over IP ไว้ว่า โทรศัพท์ผ่านอินเทอร์เน็ต ทำงานบนมาตรฐานเปิด จึงแตกต่างจากเครือข่ายโทรศัพท์พื้นฐาน ที่ต้องถูกควบคุมอย่างเข้มงวดและเสียค่าใช้จ่ายสูงในการเพิ่มลูกเล่นใหม่ ด้วย Voice over IP
คุณสามารถพัฒนาฟังก์ชันใหม่ได้เร็วเท่ากับการเขียนโปรแกรม นายไอเซนเบิร์ก ซึ่งร่วมงานกับเบลล์ แลบส์ของเอที แอนด์ ที มากว่า 12 ปี กล่าว
ในปัจจุบันการส่งสัญญาณเสียงกับข้อมูล จะถูกส่งผ่านโครงข่ายที่แยกจากกัน แต่แนวโน้มของการสื่อสารโทรคมนาคมในอนาคตอันใกล้นี้ จะเป็นลักษณะการรวมบริการหลายๆ อย่างไว้ในโครงข่ายเดียว ซึ่งสามารถให้บริการได้ทั้งสัญญาณเสียง, ข้อมูล, ภาพ ภายใต้โครงข่าย แบบแพ็คเกจ โดยการส่งข้อมูลทั้งสัญญาณภาพ และเสียงเป็นชุดของข้อมูล ที่สัญญาณเสียง จะถูกแปลงเป็นข้อมูล ก่อนที่จะถูกส่ง ในโครงข่าย โดยใช้ไอพีโปรโตคอล (Internetworking Protocol: IP) ซึ่งกำลังเป็นสิ่งทีได้รับ ความสนใจ เป็นอย่างมาก ทั้งในส่วนขององค์กร ธุรกิจ และผู้ให้บริการโครงข่ายหลายราย
ส่วนสิ่งที่ผลักดันให้ VoIP ภายใต้ ไอพี เทเลโฟนนี่ (IP Telephony) เป็นที่ต้องการทางด้านการตลาด คือ
ประการแรก โอกาสที่จะติดต่อ สื่อสารระหว่างประเทศ โดยผ่านเครือข่ายอินเทอร์เน็ต หรืออินทราเน็ต โดยมีราคาที่ถูกกว่าโครงข่ายโทรศัพท์ทั่วไป
ประการ 2 การพัฒนารูปแบบการสื่อสารใหม่ๆ เพิ่มขึ้นในปัจจุบัน โดยที่ส่วนหนึ่งถูกพัฒนาขึ้นให้สามารถใช้งานใน VoIP ทำให้สามารถติดต่อสื่อสารได้กว้างไกลมากขึ้น
ประการ 3 การเป็นที่ยอมรับ และรับเอาคอมพิวเตอร์เข้ามาใช้ในชีวิตประจำวัน ในช่วง 10 ปีที่ผ่านมาอย่างมากมาย รวมทั้งการเพิ่ม จำนวนขึ้นของผู้ใช้งานอินเทอร์เน็ตในปัจจุบัน เป็นส่วนหนึ่งที่ทำให้ VoIP ได้รับความนิยมในการติดต่อสื่อสาร
ประการ 4 มีการใช้ประโยชน์จากระบบ Network ที่มีการพัฒนาให้ดียิ่งๆ ขึ้นไปในปัจจุบัน ให้สามารถใช้งาน ได้ทั้งในการส่งข้อมูล และเสียงเข้าด้วยกัน
ประการ 5 ความก้าวหน้าทางด้านการประมวลผลของคอมพิวเตอร์ ช่วยลดต้นทุนในการสร้างเครือข่ายของ VoIP ในขณะที่ ความสามารถ การให้บริการมีมากขึ้น ส่งผลให้ธุรกิจต่างๆ เข้ามาร่วมใน VoIP มากขึ้น
ประการ 6 ความต้องการที่จะมีหมายเลขเดียวในการติดต่อสื่อสารทั่วโลก ทั้งด้านเสียง, แฟกซ์ และข้อมูล ถึงแม้ว่าบุคคลนั้น จะย้ายไปที่ใด ก็ตามก็ยังคงสามารถใช้หมายเลขเดิมได้ เป็นความต้องการของผู้ใช้งานและธุรกิจ
ประการ 7 การเพิ่มขึ้นอย่างมากมายของการทำรายการต่างๆ บน e-Commerce ในปัจจุบัน ผู้บริโภคต่างก็ต้องการการ บริการที่มีคุณภาพ และมีการโต้ตอบกันได้ระหว่างที่กำลังใช้ อินเทอร์เน็ตอยู่ ซึ่ง VoIP สามารถเข้ามาช่วยในส่วนนี้ได้
ประการ 8 การเติบโตอย่างรวดเร็วของ Wireless Communication ในปัจจุบัน ซึ่งผู้ใช้ในกลุ่มนี้ต้องการ การติดต่อสื่อสาร ที่ราคาถูกลง แต่มีความยืดหยุ่นในการใช้งาน ดังนั้น ตลาดกลุ่มนี้ถือว่า เป็นโอกาสของ VoIP
จากอดีตมีการส่งข้อมูลผ่านโครงข่ายวงจรของชุมสายโทรศัพท์ (Circuit Switching) ทำให้เกิดการใช้งานโครงข่ายได้ ไม่เต็มประสิทธิภาพ มากเท่าที่ควร เพราะแต่ละวงจร หรือเส้นทางถูกกำหนดให้ผู้ใช้เพียงคนเดียวเท่านั้น แม้ว่าวงจร หรือเส้นทางนั้นๆ จะว่างอยู่ก็ตาม แต่ในปัจจุบันเริ่มมีการใช้งานแบบแพ็คเกจสวิตชิ่ง (Packet Switching) มากขึ้น โดยการแบ่งข้อมูลที่จะส่งออกเป็นแพ็คเกจย่อยๆ และทำการส่งไปตามเส้นทางต่างๆ กัน อันเป็นการกระจายทราฟฟิก (Traffic) ทั้งหมดในโครงข่ายให้ใช้งานได้อย่างเต็มประสิทธิภาพ ทำให้โครงข่ายมีความยืดหยุ่นและคล่องตัวมากขึ้น ซึ่งหลักการของแพ็คเกจ สวิตชิ่งนี้ได้นำมาใช้เป็น Voice Over Packet เนื่องจากมีการปรับปรุง การทำงาน (Performance) บน Packet Switching ทำให้ Performance per Cost ของ Packet Switching ในอนาคตดีกว่า Circuit Switching
ทิศทางของการใช้บริการโทรศัพท์แบบเสียง มีแนวโน้มของการเจริญเติบโตค่อนข้างต่ำ ในขณะที่อัตราการเจริญ เพิ่มของการ ใช้โทรศัพท์แบบข้อมูลมีการเติบโตอย่างรวดเร็ว อันเนื่องจากการใช้งานที่แพร่หลายในทั่วโลก และนับจากที่เทคโนโลยีอินเทอร์เน็ต ได้พัฒนามาจนกระทั่งระบบโทรศัพท์บนอินเทอร์เน็ต (VoIP)
ทิศทางบริการแห่งยุค
Voice over IP เกิดขึ้นพร้อมๆ กับการให้บริการอินเทอร์เน็ต และได้กลายเป็นบริการยอดนิยมของผู้ที่เชี่ยวชาญด้านคอมพิวเตอร์ และนักศึกษา ซึ่งมีเวลาแต่ไม่มีเงิน เมื่อไม่นานมานี้ และในปัจจุบัน Voice over IP ก็กำลังได้รับความนิยมจากผู้ใช้เพิ่มมากขึ้นเรื่อยๆ การไม่สามารถเปิดให้บริการโทรศัพท์ด้วยเสียงผ่านอินเทอร์เน็ตจากเครือข่าย ที่มีอยู่เดิม อาจทำให้ผู้ให้บริการ เช่น เวอริซอน, เอสบีซี และเบลล์เซาธ์ ต้องสูญเสียส่วนแบ่งในตลาดโทรคมนาคมมูลค่า 200,000 ล้านดอลลาร์ได้ เนื่องจาก เมื่อใช้ Voice over IP ลูกค้ามีอิสระในการใช้เครือข่ายของผู้ให้บริการเดิม หรือจะเปลี่ยนผู้ให้บริการใหม่ อย่างเช่น บริษัทผู้ให้บริการทีวีตามสาย (เคเบิล ทีวี) หรือธุรกิจเกิดใหม่ อย่าง Net2Phone และ Vonage ได้ ประกอบกับ การใช้งาน Voice over IP ไม่จำเป็นต้องโทรศัพท์ผ่านพีซีที่ใช้ไมโครโฟนเป็นอุปกรณ์เสริมอีกต่อไป แม้ว่าอุปกรณ์ดังกล่าว กำลังจะกลับมาอีกครั้งตามกระแสนิยมบริการ อย่าง Skype ซึ่งพัฒนาขึ้นโดยอาศัยสถาปัตยกรรมของคาซา และทำให้การโทรศัพท์แบบพีซีกับพีซีง่ายขึ้น ขณะที่คิดค่าธรรมเนียมเหมือนโทรศัพท์ทั่วไป คือ เพียง 100 ดอลลาร์เท่านั้น นับตั้งแต่เปิดตัวไปเมื่อเดือนเมษายนที่ผ่านมา โวเนจ ผู้ให้บริการ Voice over IP ชั้นนำ สามารถดึงดูดให้ลูกค้า 85,000 คน จ่ายค่าบริการ 15 - 35 ดอลลาร์ต่อเดือน
แนวโน้มวงการโทรคมฯ
เมื่อเร็วๆนี้ บริษัท นีเมอร์เทส รีเสิร์ช ในชิคาโก ทำสำรวจ 42 บริษัท ซึ่งคิดเป็น 70% ของบริษัทที่มีรายได้มากกว่า 1,000 ล้านดอลลาร์ และพบว่า ประชาชนเกือบ 2 ใน 3 ใช้โทรศัพท์ผ่านอินเทอร์เน็ต ขณะที่อีก 20% ที่เหลือ กำลังทดลองใช้เทคโนโลยีดังกล่าว จึงไม่แปลกใจว่าทำไมเมื่อเดือนธันวาคมที่ผ่านมา เอที แอนด์ ที, เควสต์, คอกซ์ คอมมิวนิเคชันส์, และไทม์ วอร์เนอร์ เทเลคอม จึงตบเท้าทยอยเปิดตัวบริการ Voice over IP ของตัวเอง
Voice over IP สร้างความตื่นเต้นให้กับลูกค้า นางแคธี มาร์ติน รองประธานอาวุโสเอที แอนด์ ที ผู้ซึ่งผลักดันให้บริการโทรศัพท์ผ่านอินเทอร์เน็ต ของมา เบลล์ กลายเป็นบริการยอดนิยม 100 อันดับแรกในตลาดผู้บริโภคทั่วไปและองค์กรธุรกิจของสหรัฐ กล่าว พร้อมเสริมว่า คำว่า แจ๋ว ไม่ได้ถูกนำมาใช้ในภาคโทรคมนาคมเลย นับตั้งแต่การมาถึงของโทรศัพท์ในทศวรรษ 1950 เป็นต้นมา แต่ความยืดหยุ่นของโทรศัพท์ผ่านอินเทอร์เน็ต อาจทำให้ผู้ใช้ต้องอุทานคำดังกล่าว เพื่อแสดงออกถึงความพอใจในการใช้งาน
ขณะที่นายเดวิด ไอเซนเบิร์ก ที่ปรึกษาด้านโทรคมนาคมอิสระ ขยายความเรื่องความยืดหยุ่นของบริการ Voice over IP ไว้ว่า โทรศัพท์ผ่านอินเทอร์เน็ต ทำงานบนมาตรฐานเปิด จึงแตกต่างจากเครือข่ายโทรศัพท์พื้นฐาน ที่ต้องถูกควบคุมอย่างเข้มงวดและเสียค่าใช้จ่ายสูงในการเพิ่มลูกเล่นใหม่ ด้วย Voice over IP
คุณสามารถพัฒนาฟังก์ชันใหม่ได้เร็วเท่ากับการเขียนโปรแกรม นายไอเซนเบิร์ก ซึ่งร่วมงานกับเบลล์ แลบส์ของเอที แอนด์ ที มากว่า 12 ปี กล่าว
ในปัจจุบันการส่งสัญญาณเสียงกับข้อมูล จะถูกส่งผ่านโครงข่ายที่แยกจากกัน แต่แนวโน้มของการสื่อสารโทรคมนาคมในอนาคตอันใกล้นี้ จะเป็นลักษณะการรวมบริการหลายๆ อย่างไว้ในโครงข่ายเดียว ซึ่งสามารถให้บริการได้ทั้งสัญญาณเสียง, ข้อมูล, ภาพ ภายใต้โครงข่าย แบบแพ็คเกจ โดยการส่งข้อมูลทั้งสัญญาณภาพ และเสียงเป็นชุดของข้อมูล ที่สัญญาณเสียง จะถูกแปลงเป็นข้อมูล ก่อนที่จะถูกส่ง ในโครงข่าย โดยใช้ไอพีโปรโตคอล (Internetworking Protocol: IP) ซึ่งกำลังเป็นสิ่งทีได้รับ ความสนใจ เป็นอย่างมาก ทั้งในส่วนขององค์กร ธุรกิจ และผู้ให้บริการโครงข่ายหลายราย
ส่วนสิ่งที่ผลักดันให้ VoIP ภายใต้ ไอพี เทเลโฟนนี่ (IP Telephony) เป็นที่ต้องการทางด้านการตลาด คือ
ประการแรก โอกาสที่จะติดต่อ สื่อสารระหว่างประเทศ โดยผ่านเครือข่ายอินเทอร์เน็ต หรืออินทราเน็ต โดยมีราคาที่ถูกกว่าโครงข่ายโทรศัพท์ทั่วไป
ประการ 2 การพัฒนารูปแบบการสื่อสารใหม่ๆ เพิ่มขึ้นในปัจจุบัน โดยที่ส่วนหนึ่งถูกพัฒนาขึ้นให้สามารถใช้งานใน VoIP ทำให้สามารถติดต่อสื่อสารได้กว้างไกลมากขึ้น
ประการ 3 การเป็นที่ยอมรับ และรับเอาคอมพิวเตอร์เข้ามาใช้ในชีวิตประจำวัน ในช่วง 10 ปีที่ผ่านมาอย่างมากมาย รวมทั้งการเพิ่ม จำนวนขึ้นของผู้ใช้งานอินเทอร์เน็ตในปัจจุบัน เป็นส่วนหนึ่งที่ทำให้ VoIP ได้รับความนิยมในการติดต่อสื่อสาร
ประการ 4 มีการใช้ประโยชน์จากระบบ Network ที่มีการพัฒนาให้ดียิ่งๆ ขึ้นไปในปัจจุบัน ให้สามารถใช้งาน ได้ทั้งในการส่งข้อมูล และเสียงเข้าด้วยกัน
ประการ 5 ความก้าวหน้าทางด้านการประมวลผลของคอมพิวเตอร์ ช่วยลดต้นทุนในการสร้างเครือข่ายของ VoIP ในขณะที่ ความสามารถ การให้บริการมีมากขึ้น ส่งผลให้ธุรกิจต่างๆ เข้ามาร่วมใน VoIP มากขึ้น
ประการ 6 ความต้องการที่จะมีหมายเลขเดียวในการติดต่อสื่อสารทั่วโลก ทั้งด้านเสียง, แฟกซ์ และข้อมูล ถึงแม้ว่าบุคคลนั้น จะย้ายไปที่ใด ก็ตามก็ยังคงสามารถใช้หมายเลขเดิมได้ เป็นความต้องการของผู้ใช้งานและธุรกิจ
ประการ 7 การเพิ่มขึ้นอย่างมากมายของการทำรายการต่างๆ บน e-Commerce ในปัจจุบัน ผู้บริโภคต่างก็ต้องการการ บริการที่มีคุณภาพ และมีการโต้ตอบกันได้ระหว่างที่กำลังใช้ อินเทอร์เน็ตอยู่ ซึ่ง VoIP สามารถเข้ามาช่วยในส่วนนี้ได้
ประการ 8 การเติบโตอย่างรวดเร็วของ Wireless Communication ในปัจจุบัน ซึ่งผู้ใช้ในกลุ่มนี้ต้องการ การติดต่อสื่อสาร ที่ราคาถูกลง แต่มีความยืดหยุ่นในการใช้งาน ดังนั้น ตลาดกลุ่มนี้ถือว่า เป็นโอกาสของ VoIP
จากอดีตมีการส่งข้อมูลผ่านโครงข่ายวงจรของชุมสายโทรศัพท์ (Circuit Switching) ทำให้เกิดการใช้งานโครงข่ายได้ ไม่เต็มประสิทธิภาพ มากเท่าที่ควร เพราะแต่ละวงจร หรือเส้นทางถูกกำหนดให้ผู้ใช้เพียงคนเดียวเท่านั้น แม้ว่าวงจร หรือเส้นทางนั้นๆ จะว่างอยู่ก็ตาม แต่ในปัจจุบันเริ่มมีการใช้งานแบบแพ็คเกจสวิตชิ่ง (Packet Switching) มากขึ้น โดยการแบ่งข้อมูลที่จะส่งออกเป็นแพ็คเกจย่อยๆ และทำการส่งไปตามเส้นทางต่างๆ กัน อันเป็นการกระจายทราฟฟิก (Traffic) ทั้งหมดในโครงข่ายให้ใช้งานได้อย่างเต็มประสิทธิภาพ ทำให้โครงข่ายมีความยืดหยุ่นและคล่องตัวมากขึ้น ซึ่งหลักการของแพ็คเกจ สวิตชิ่งนี้ได้นำมาใช้เป็น Voice Over Packet เนื่องจากมีการปรับปรุง การทำงาน (Performance) บน Packet Switching ทำให้ Performance per Cost ของ Packet Switching ในอนาคตดีกว่า Circuit Switching
ทิศทางของการใช้บริการโทรศัพท์แบบเสียง มีแนวโน้มของการเจริญเติบโตค่อนข้างต่ำ ในขณะที่อัตราการเจริญ เพิ่มของการ ใช้โทรศัพท์แบบข้อมูลมีการเติบโตอย่างรวดเร็ว อันเนื่องจากการใช้งานที่แพร่หลายในทั่วโลก และนับจากที่เทคโนโลยีอินเทอร์เน็ต ได้พัฒนามาจนกระทั่งระบบโทรศัพท์บนอินเทอร์เน็ต (VoIP)
|| vcharkarn.com || voip.n3amedia.biz